Hadoop 是用 Java 編程的,因此用 Java 來開發相關應用是最方便的,不過 Hadoop 也支援用其他語言開發,如 C++、Python、Ruby。Python 的性能雖然比不上 Java 或 C++,但優點是有豐富的數據處理庫,如 Pandas 和 NumPy,因此應用程序如果涉及大量的數據處理和轉換,Python 會是個不錯的選擇。
程式碼
這次參賽的程式碼都會放在 Big-Data-Framework-30-days,建議大家直接把整個 repo clone 下來,然後參考 README 進行基本設置,接著直接 cd 到今天的資料夾內。
前幾天有提到 MapReudce 的流程是 Input > Split > Map > Shuffle and Sort > Reduce > Output,而實際上我們需要開發的只有 Map 以及 Reduce 兩個部分,其餘部分都交由 Hadoop 來幫我們處理就好~
Hadoop Streaming 就是一個協助我們創建和運行 MapReduce 作業的工具,我們可以撰寫自己的腳本來充當 Mapper 與 Reducer,用法如下:
mapred streaming \
-input myInputDirs \ #
-output myOutputDir \
-mapper /path/to/mapper \
-reducer /path/to/reducer \
-file /path/to/file
網路上很多是舊版做法 (
hadoop jar $HADOOP_HOME/hadoop-streaming.jar),現在已經不能用了喔!
由於我們是使用 Python 來開發程式,我們無法直接使用 Hadoop API (JAVA) 來傳輸數據,所以要改為使用標準輸入 (STDIN) 和標準輸出(STDOUT) 來作為數據傳遞通道,優點是通用性,因為所有程式語言都支持標準 I/O 通道,缺點是效率不一定是最好的。
Mapper 負責讀取輸入數據,將每個拆分的數據進行處理,並輸出鍵值對 (key-value pair)。
#!/usr/bin/env python
import sys
for line in sys.stdin:
line = line.strip().lower()
words = line.split()
# give every word 1 count
for word in words:
print(f'{word}\t1')
這裡程式邏輯很簡單,其實單純是做數據格式轉換而已,斷詞的部分簡單用 split 來處理,如果想要斷的乾淨點或做其他轉換可以自己修改程式碼。
Reducer 負責讀取 Mapper 的輸出結果,將相同key的數據進行合併、計算或其他處理,並輸出鍵值對 (key-value pair) 。
#!/usr/bin/env python
import sys
curr_word = None
curr_count = 0
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t')
count = int(count)
# the if condition works only when the input is sorted
if curr_word != word:
if curr_word :
print(f"{curr_word}\t{curr_count}")
curr_word = word
curr_count = 0
curr_count += count
# output last word
if curr_word:
print(f"{curr_word}\t{curr_count}")
這裡程式邏輯也很簡單,遇到相同的詞就把 count 加起來,遇到不同的就重設並印出前一個詞的合計。
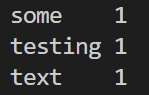
# echo "some testing text" | python <path/to/mapper.py> | sort | python <path/to/reducer.py>
echo "some testing text" | python 30days/day09/mapper.py | sort | python 30days/day09/reducer.py
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
在 day09 資料夾中我準備了一些測試用檔案,執行 uploading.py 即可上傳測試檔案 (要放在同個資料夾內),程式碼放下面大家自己看。
python 30days/day09/uploading.py
uploading.py
# make connections
from hdfs import InsecureClient
client = InsecureClient("http://localhost:9870/", user='mengchiehliu')
# make directory
client.makedirs('day09/input')
# upload testing files
import os
local_dir = os.path.dirname(__file__)
client.upload(hdfs_path="day09/input/test_text_1.txt", local_path=f'{local_dir}/test_text_1.txt', overwrite=True)
client.upload(hdfs_path="day09/input/test_text_2.txt", local_path=f'{local_dir}/test_text_2.txt', overwrite=True)
client.upload(hdfs_path="day09/input/test_text_3.txt", local_path=f'{local_dir}/test_text_3.txt', overwrite=True)
mapred streaming \
-input day09/input \
-output day09/output \
-mapper 30days/day09/mapper.py \
-reducer 30days/day09/reducer.py
因為是在偽分布模式 (單一節點) 執行,所以不用帶 file option
事實上,因為 reducer 做的內容就是加總而已,因此 Hadoop 早就幫我們封裝成一個 aggregate 功能,所以我們也直接寫:
mapred streaming \
-input day09/input \
-output day09/output \
-mapper 30days/day09/mapper.py \
-reducer aggregate
hadoop fs -cat day09/output/*
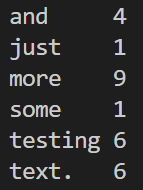
今天介紹了 MapReduce 的基本應用 WordCount,簡單複習一下,我們使用了 Hadoop Streaming,讀取存儲在 HDFS 內的文字檔,經過 Mapper 與 Reducer 運算後產出每個詞的出現頻率。
明天會介紹如何用 Hive 來在 Hadoop 中處理結構化數據。
Hadoop Streaming
Writing An Hadoop MapReduce Program In Python


 iThome鐵人賽
iThome鐵人賽